
简介
图像放大算法大致有两种:传统图像放大算法(Lantent、Lanczos、Nearest)
AI图像放大算法(4x-UltraSharp、BSRGAN、ESRGAN等)
传统图像放大算法是基于插值算法,计算出图像放大后新位置的像素值。AI图像放大算法,比一般的传统图像放大算法效果更好。
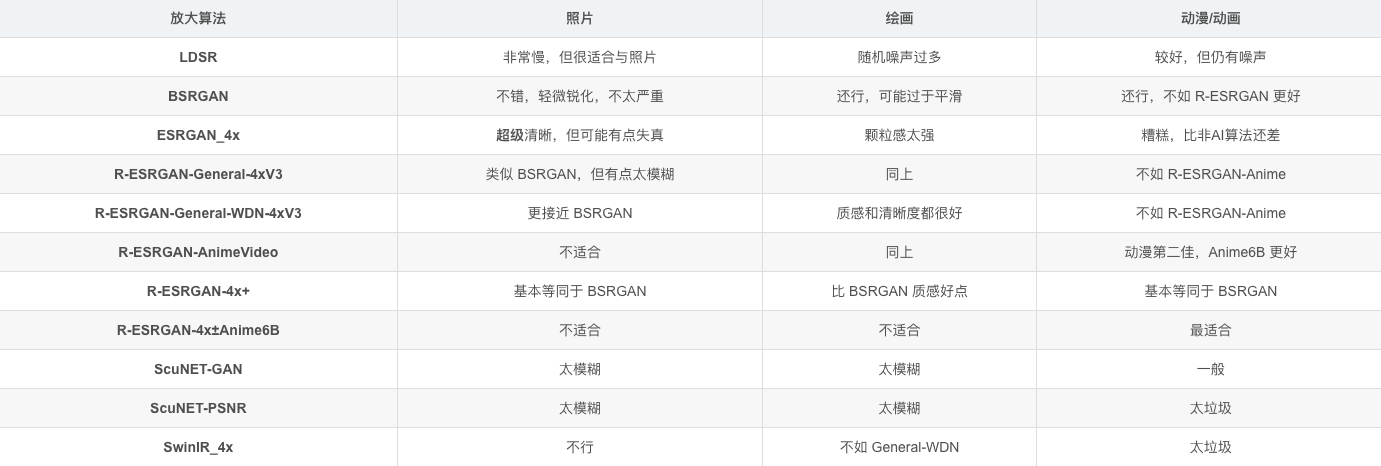
推荐放大算法 ESRGAN系列 和 4X-UltraSharp
R-ESRGAN 4x+ 适用于写实图片,ESRGAN 系列算法放大后会对细节进行重绘。如果单纯进行放大,推荐使用 ESRGAN_4x,适用于照片写实类。
R-ESRGAN 4x+ Anime6B 适用于二次元类图片或二三次元混合图片
对比
模型
GPEN (Generative Prior Embedded Network)、GFPGAN (GFP-Guided Photo Face Restoration) 和 CodeFormer 是三个在图像处理和修复领域具有代表性的深度学习模型。它们虽然都涉及图像恢复和增强
GPEN :
– 任务焦点:GPEN 主要用于超分辨率(SR)任务,特别是基于单幅低分辨率图像生成高分辨率图像。
– 技术特点:GPEN 引入了一种新颖的“生成性先验嵌入”(Generative Prior Embedding, GPE)模块,通过学习一个潜在空间,将低分辨率图像映射到高维空间,再通过解码器生成高分辨率图像。这种方法结合了传统超分辨率方法中的先验知识与生成对抗网络(GAN)的优势。
– 优势:GPEN 能够有效地捕捉图像的结构和纹理信息,生成细节丰富、自然逼真的高分辨率图像。其生成性先验嵌入模块有助于提高模型的泛化能力和鲁棒性。对于图像中人脸很小的情况,GPEN的表现最优秀。还有就是GPEN背景增强的效果最好。
– 劣势:可能在处理极端退化或非常规分辨率提升比例的任务时,性能不如专门为此设计的模型。此外,GPEN 的训练可能比其他模型更为复杂,需要对生成性先验嵌入模块进行细致调整。也就是说,当图像中人脸极不清晰的时候,GPEN的保真度很差,与原人脸相差太大。
GFPGAN :
– 任务焦点:GFPGAN 特别专注于人脸照片的恢复,尤其是老照片、低分辨率或损坏人脸的修复。
– 技术特点:GFPGAN 利用预训练的生成对抗网络(GAN)模型(如StyleGAN)作为先验知识,通过引导滤波器预测网络(Guided Filter Prediction Network, GFPNet)来指导人脸修复过程。它还引入了感知损失、身份保持损失等多任务损失函数,确保恢复的人脸既保留原始身份特征,又具有高清晰度和自然外观。
– 优势:GFPGAN 在人脸恢复任务上表现出色,能够恢复极高细节的人脸图像,同时保持身份一致性。其利用预训练GAN模型作为先验知识的方法有效利用了大规模无监督数据,提高了恢复效果。经过长期使用,个人感觉GFPGAN的面部增强效果和保真度之间的平衡,是把握的最好的,而且速度最快。
– 劣势:GFPGAN 专注于人脸修复,对于非人脸或非人脸主导的图像恢复任务可能效果不佳。此外,由于涉及到复杂的多任务损失和预训练模型引导,其训练和应用可能较为复杂。
背景增强效果很差,修复后的脸部过渡处理不好,有明显边界。
CodeFormer:
– 任务焦点:CodeFormer 主要面向图像修复、去噪、超分辨率等更广泛的图像恢复任务,尤其擅长处理含有结构信息的图像(如文本、线条、边缘)。
– 技术特点:CodeFormer 结合了Transformer架构与编解码器结构,通过自注意力机制捕获全局依赖关系,并通过局部卷积保持局部细节。它使用多层感知机(MLP)作为解码器,生成图像补丁的像素值。
– 优势:CodeFormer 由于采用了Transformer架构,能够有效地处理长距离依赖关系,特别适合于恢复含有明显结构信息的图像。其通用性强,能够在多种图像恢复任务上取得良好效果。CodeFormer修复后的面部过渡自然,无明显边界。
– 劣势:相较于专门为特定任务(如人脸恢复)设计的模型,CodeFormer 可能需要更多的训练数据和计算资源才能达到最佳性能。对于高度专业化的任务(如人脸恢复中的身份保持),可能需要额外的技术调整或损失函数来增强针对性。速度相比GFPGAN略显慢。